Initially, I wasn’t sure whether to write about this migration project, but when I randomly asked if people would be interested, the response was overwhelming. This was a long, kind of boring, very repetitive, and at times incredibly frustrating project, but I learned a lot, and maybe someone else will learn from this too. There may be far better ways to move this amount of data. In the path I went down, there was a huge amount of juggling that had to take place (I’ll explain that later). Thankfully, I’m a decent juggler.
While most people are probably interested in what we do with our primary SQL Servers (the servers that run Stack Overflow and the Stack Exchange network of sites), this post isn’t about those servers. This post is about what I called a miscellaneous server in a previous post - more specifically, it’s about the migration of our traffic log data.
Background
Our HAProxy1 logs aka traffic logs, are currently stored on two SQL Servers, one in New York, and one in Colorado. While we store a minimal summary of the traffic data, we have a lot of it. At the beginning of 2019, we had about 4.5 years of data, totaling about 38TB. The database was initially designed to have a single table for each day. This meant that at the start of 2019 we had approximately 1600 tables in a single database with multiple database files (due to the 16TB size limit of data files). Each table had a clustered columnstore index, which held anywhere from 100-400 million rows in it.
I had to move the data from their existing daily tables into a new structure — one table for each month. This needed to be completed on both the NY and CO servers, and the data was stored on spinny drives (Eeek). No matter what, it was going to be painful and slow.
Oh, and to make things even more complicated, this had to be done with minimal free disk space on the existing servers. The servers had a 44TB spinny drive partition, and we were using 36-38TB of it, depending on the server. This meant I’d be following these steps throughout the process:
- migrate data to the new format
- delete old data
- shrink old database files…yeah, I know, but I had no choice
- repeat over, and over, and over again
I fully expected the process to take months, and it did — after hitting delays in getting new servers the entire project took about 11 months.
1 Note: If you’re interested, my colleague, Nick Craver (b | t), wrote extensively about our monitoring on his blog and gave an overview of our HAProxy usage.
Things to Remember
Before I get started there are a few things I need to mention which impacted the project:
- I work remote 100% of the time, so I would not be able to run any of the processes from my local computer. Everything needed to be executed on a machine that was constantly connected to the network, so there wouldn’t be any VPN failures.
- I needed to run this on two separate machines. I was doing this on SQL servers in two different datacenters, I needed a machine in the same location, so I wouldn’t have to deal with slowness over the network.
- We have jump boxes that we use for various things at Stack Overflow, and we have one in NY and in CO, which were perfect to run the migration
- The old database was still being used in a live production environment, meaning that as I was moving data, we were constantly adding a new table daily. In other words, I had a moving target
- The databases are in
simple recoveryso we don’t have to deal with transaction logs. Our backup is the original source log files and the pair of SQL Servers - NY and CO - are copies of each other.
The bullets above were pain points throughout the project. Being disconnected from the VPN meant I’d have to reconnect to monitor the migration progress. Getting booted from a jumpbox, meant that whatever process was running would need to be kicked off again, after some clean-up. Since we were still inserting new data I was chasing the target, the longer it took, the more data I’d be moving in the end.
Why, oh why would you do this?
I like to be miserable. Kidding.
There were lots of reasons this needed to be done, one being tech debt. We realized that the original daily table structure wasn’t ideal. If we needed to query something over several days or months, it was terrible — lots of UNION ALLs or loops to crawl through days or even months at a time was slow.
Why not delete or purge some of the data?
As I mentioned, we were dealing with very little free disk space on both servers. This data is primarily used by the developers for investigating issues and by the data team for analysis. We already had purged some data, but for the data team - more data is better.
Instead of purging, the plan was to eventually get new hardware to replace them, but we weren’t exactly sure when that would happen. The goal was to migrate the data to the new format, then when we got new servers it would be as simple as moving the drives to get the new database in place (or so we thought).
So It Begins
Each server had the following drives and approximate free space:
- a 230GB C: drive for Windows - obviously we wouldn’t put data files here
- a 3.64TB NVMe D: drive - containing tempdb, one data file, and the log file for the existing HAProxyLogs database - it was approximately 85% full
- a 44TB E: drive filled with spinny disks - with the remaining 3 data files for the HAProxyLogs database - this was anywhere from 85-90% full
There was not a lot of room to move terabytes of data to a new database on the same server.
Since new servers were on down the road, I asked about the possibility of getting more disk space. Having more space would give me some breathing room to not be so crunched during the process. After some research, it was decided that we could fit a couple of additional NVMe SSDs into both servers. We only had PCIe slots available in the server, so we ended up using U.2 NVMe drives on PCIe adapters to get us some space. The SSDs gave us a brand spanking new F: drive that was 14TB of free space. While I couldn’t move everything to the new drive, it gave me plenty of space to work with, at least, for a little bit.
Now that we had free space to use, it was time to set up the new database and begin the migration. I wrote the script to create the new database:
|
|
The database was going to have all of the old historical tables (i.e. the 40TBs) stored on the TrafficLogs_Archive filegroup, and we’d use the PRIMARY and TrafficLogs_Current for newer data being added.
You’ll notice that the TrafficLogs_Archive filegroup went on our already very full E: drive, instead of the new F: drive - more on that mistake later.
Moving All The Data
We had a database, so it was time to start the migration. To be clear, I was actually taking over a process that was started, stopped, and then punted from several years earlier. The project was on the backlog of things to be done long before I became the DBA at Stack Overflow. Back then, everyone realized what a time consuming project this would be, and since we didn’t have the resources to devote to it, the can continuously got kicked down the road. As a result, more and more tables were added making the overall task a lot larger.
Since this had been a previously abandoned project, there were already some scripts written, which meant I wasn’t totally starting from scratch. I was handed a couple of scripts to:
-
Create all of the new monthly tables
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69-- written by Nick Craver Declare @month datetime = '2015-08-01'; Declare @endmonth datetime = '2021-01-01' WHILE @month < @endmonth BEGIN Set NoCount On; Declare @prevMonth datetime = DateAdd(Month, -1, @month); Declare @nextMonth datetime = DateAdd(Month, 1, @month); Declare @monthTable sysname = 'Logs_' + Cast(DatePart(Year, @month) as varchar) + '_' + Right('0' + Cast(DatePart(Month, @month) as varchar), 2); Begin Try If Object_Id(@monthTable, 'U') Is Not Null Begin Declare @error nvarchar(400) = 'Month ' + Convert(varchar(10), @month, 120) + ' has already been moved to ' + @monthTable + ', aborting.'; Throw 501337, @error, 1; Return; End -- Table Creation Declare @tableTemplate nvarchar(4000) = ' Create Table {Name} ( [CreationDate] datetime Not Null, <insert all the columns>, Constraint CK_{Name}_Low Check (CreationDate >= ''{LowerDate}''), Constraint CK_{Name}_High Check (CreationDate < ''{UpperDate}'') ) On {Filegroup}; Create Clustered Columnstore Index CCI_{Name} On {Name} With (Data_Compression = {Compression}) On {Filegroup};'; -- Constraints exist for metadata swap Declare @table nvarchar(4000) = @tableTemplate; Set @table = Replace(@table, '{Name}', @monthTable); Set @table = Replace(@table, '{Filegroup}', 'Logs_Archive'); Set @table = Replace(@table, '{LowerDate}', Convert(varchar(20), @month, 120)); Set @table = Replace(@table, '{UpperDate}', Convert(varchar(20), @nextMonth, 120)); Set @table = Replace(@table, '{Compression}', 'ColumnStore_Archive'); Print @table; Exec sp_executesql @table; Declare @moveSql nvarchar(4000) = 'Create Clustered Columnstore Index CCI_{Name} On {Name} With (Drop_Existing = On, Data_Compression = Columnstore_Archive) On Logs_Archive;'; Set @moveSql = Replace(@moveSql, '{Name}', @monthTable); Print @moveSql; Exec sp_executesql @moveSql; End Try Begin Catch Select Error_Number() ErrorNumber, Error_Severity() ErrorSeverity, Error_State() ErrorState, Error_Procedure() ErrorProcedure, Error_Line() ErrorLine, Error_Message() ErrorMessage; Throw; End Catch set @month = dateadd(month, 1, @month) END GO -
A LINQPad script to loop through each day, starting with the earliest, and insert the data into the new table
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115-- written by Nick Craver <Query Kind="Program"> <NuGetReference>Dapper</NuGetReference> <Namespace>Dapper</Namespace> </Query> void Main() { MoveDate(new DateTime(2015, 08, 1)); DateTime date = new DateTime(2015, 08, 1); while (date < DateTime.UtcNow) { MoveDate(date); date = date.AddDays(1); } } static readonly List<string> cols = new List<string> { "<col list>" }; public void MoveDate(DateTime date) { var tableName = GetTableName(date); var destTable = GetDestTableName(date); $"Attempting to migrate {date:yyyy-MM-dd} f from {tableName} to {destTable}".Dump($"{date:yyyy-MM-dd}"); using (var conn = GetConn()) { int rowCount; try { rowCount = conn.QuerySingle<int>($"Select Count(*) From HAProxyLogs.dbo.{tableName};"); } catch (SqlException e) { (" Error migrating: " + e.Message).Dump(); return; } $" Summary for {date:yyyy-MM-dd}".Dump(); $" {rowCount:n0} row(s) in {tableName}".Dump(); var pb = new Util.ProgressBar($"{tableName} (0/{rowCount})"); pb.Dump(tableName + " copy"); Func<int> GetDestRowCount = () => conn.QuerySingle<int>($"Select Count(*) From {destTable} Where CreationDate >= @date And CreationDate < @date + 1;", new { date }); Action<long, int> UpdatePB = (copied, total) => { pb.Fraction = (double)copied / total; pb.Caption = $"{tableName} ({copied}/{total})"; }; var destRowCount = GetDestRowCount(); $" {destRowCount:n0} row(s) in {destTable}".Dump(); if (destRowCount > 0) { $"Rows found in destiation table - aborting!".Dump(); return; } var reader = conn.ExecuteReader($"Select {string.Join(",", cols)} From HAProxyLogs.dbo.{tableName};"); using (SqlConnection dest = GetConn()) { dest.Open(); using (SqlBulkCopy bc = new SqlBulkCopy(dest)) { bc.BulkCopyTimeout = 5*60; bc.BatchSize = 1048576; bc.NotifyAfter = 100000; bc.DestinationTableName = GetDestTableName(date); bc.SqlRowsCopied += (e, s) => UpdatePB(s.RowsCopied, rowCount); foreach (var c in cols) { bc.ColumnMappings.Add(c, c); } try { bc.WriteToServer(reader); } catch (Exception ex) { Console.WriteLine(ex.Message); } finally { reader.Close(); } } var destFinalCount = GetDestRowCount(); } } } public SqlConnection GetConn() => new SqlConnection(new SqlConnectionStringBuilder { DataSource = "servername", InitialCatalog = "TrafficLogs", IntegratedSecurity = true }.ToString()); public string GetTableName(DateTime dt) => $"Log_{dt:yyyy_MM_dd}"; public string GetDestTableName(DateTime dt) => $"HAProxyLogs_{dt:yyyy_MM}";
Ideally, this was going to be as simple as kicking off the LINQPad script, and letting it run in the background looping through all the tables. I thought I wouldn’t have to worry about it, but things are never really that easy.
I started the migration in Colorado, on January 14, 2019 (yes, I know the exact date). Pulling millions of rows of data from spinny drives, and then inserting it back into new tables on those same spinny drives was slow. By day 2, knew this was going to be painful. My original plan was to run the migration in Colorado first, then in New York. However, once I saw how slow each table was taking, I decided to run them simultaneously. About a week later, I kicked off the New York data migration.
Data Migration Issues
Early on, I hit various issues that I needed to work through. Some of these were easy fixes, others not so much.
Script Timeouts
The first issue was with the C# script. The script periodically timed-out when querying the database. After adjusting the settings, I crossed my fingers and hoped it would continue to work, which it did, for the most part.
Random Script Errors
Next, I ran into an issue, where the script would continue to the next table, aka day, if there was an error. That was terrible because we wanted the data to be inserted in date order, for the clustered columnstore index. If the script errored and moved on to the next day, cleanup would need to be done for the day that didn’t finish. At that point, I’d have to start the process over for that particular day.
You might be wondering what I mean by “cleanup”.
Let me take a quick step back and explain the old process. The original table structure aka the daily tables were rowstore with a generic identity (ID) column to make each row unique. After 14 days, we would drop the primary key from the table, and add a clustered columnstore index. Even though the conversion to a clustered columnstore occurred, the ID column would remain.
In the new table, we dropped the ID column. Dropping this column meant, trying to figure out the uniqueness of the rows inserted before a failure would be incredibly difficult. It was far easier, in the event of a failure, to just delete everything from the table for that day, and everything after that day (if it moved to another table), and restart the process.
Data Validation
I realized I needed to validate that the total number of rows inserted into the new table matched the total number of rows from the old daily table. Sounds easy, right? Well, not necessarily.
Sure, the original tables were per day, but there were cases where instead of containing data from date 00:00-23:59 it would potentially include some rows from date+1. This was a known issue (due to latency of logs arriving from HAProxy), and I was told the totals didn’t have to match perfectly - if we lost some rows, it was fine. The thing is, when you’re responsible for moving data from one system to another, you really want things to match…perfectly.
Because of the stragglers from a different day, I couldn’t just query the total rows from the old table and verify that the new table contained the same count. I had to come up with a way to query the count by day. I did this by adding a column to the new table called OriginalLogTable and then populating it with the name of the old table, for example Log_2019_07_01. Having this column allowed me to compare the count of rows in the old table, with the count in the new table by grouping by the OriginalLogTable. This solved my problem because when I finished a month, I could easily verify that each day matched between the old and new tables, using the script below:
|
|
Column Changes
I also discovered that we added new columns after the original daily tables were designed. This meant that over the course of the data migration the table structure would change. I adjusted the LinqPad script so it would add the new columns when needed based on date, this would make sure it continued to work and we wouldn’t skip new columns.
There were many more issues which involved debugging the script, but eventually I had a C# script that fixed all of the above problems. The new script looked a little like this:
|
|
It’s So Slow
We all knew this was going to be a slow process, but I don’t think anyone realized how slow. I did everything I could think of to try and speed up the script.
It took about 2-2.5 hours to insert each old table into the new table. By the middle of February, I had:
- 1332 tables left to migrate in New York
- and 782 tables left in Colorado
At the rate it was going, I knew it was going to take months to complete.
I went back to the drawing board to figure out some way to move the data faster. Obviously, I wanted to follow the same steps - insert old data, verify the row count matches, move to the next day, repeat - I used the C# script as my model - I mean it worked, it was just a little slow. I tried a bunch of different things, none were blazingly fast:
- an SSIS package - sorry SSIS fans, this was even slower and I won’t embarrass myself by sharing it
- a SQL script using dynamic SQL - this was also pretty slow
|
|
- a PowerShell version - slow but seemed to be more stable than the original C# script
|
|
All of my options were slow.
I ended up using the PowerShell option because I could easily run multiple months at once. I had 3 PowerShell sessions going, which let me chew through 3 months at a time. It was far easier to run several months in PowerShell than with the C# script. Utilizing PowerShell allowed me to get through a lot more data in a shorter amount of time. Don’t get me wrong it was still slow - each session was moving about a month of tables in about a week of work - but at least I was moving more data and chasing the target slightly faster.
While the PowerShell script wasn’t perfect, and I still hit issues with timeouts and errors, it overall worked better. Now that I had a somewhat working process that didn’t need daily hand-holding, it was time to focus on some of the other problems with the migration.
Continuous Issues of No Free Disk Space
When your servers are already limited in free space and you have to move 40TB of data around on the same server, it becomes a little like whack-a-mole to get things moved. I had to get creative to free up space while continuing to move all the data to the new format.
Deleting and Shrinking
Yes, you read that right. Shrinking. Before I get to that, let me explain why I needed to do this.
We didn’t have new hardware yet and these were production SQL Servers - meaning the old database was still receiving new data and we were adding a new table everyday. As I was moving tables to the new database, we were adding tables with hundreds of millions of rows of data to the old database. This was all happening on the exact same server and drive with minimal free space.
Hence the need to juggle.
After moving each month, I would do a final validation, then it was time for some cleanup. This included deleting all of the daily tables for the month that were just migrated, as well as dropping the OriginalLogTable column from the monthly table in the new database. The daily tables were no longer needed because we had the data in the new table, so getting rid of duplicate data would allow me to gain back disk space…sort of.
I say sort of, because I was just moving data on the same drives. We changed formats from daily tables to monthly tables, and while we got better compression in the new tables, there weren’t huge gains in free space. We had the same number of rows of data stored in fewer tables, which meant less bits in the long run, but in order to gain back the space allocated to the old data files, I had to shrink them.

As I moved the data from the old files, I was increasing the size of the new data files. This was all being done on the E: drive that was 85-90% full, which I mentioned above. I was constantly trying to keep the used disk space in check.
It was quite a balancing act.
Each month of data was anywhere from 300GB to 1TB in size, and the 3 old data files were approximately 12TB each. At the end of each migration, I tried to shrink the old database files by the amount we just deleted. This took several attempts to get something that worked well.
Initially, I naively tried to run DBCC SHRINKFILE(FileName, TRUNCATEONLY) to free up space. As I expected, that did not work.
Next, I tried to run DBCC SHRINKFILE(FileName, CurrentFileSize - SizeOfDataJustDeleted) on each file. That didn’t work either. Well to be clear, it would have if we had more drive space on the D: drive where the log file was stored. The D: drive was already about 85% full with tempdb, the HAProxyLogs log file, and another datafile. When you run DBCC SHRINKFILE and let’s say you want to shrink a file by 300GB, then you need to have the ability to increase your database transaction log file by the amount you’re trying to shrink. Since we were already constrained on drive space where the t-log was stored, I wasn’t able to shrink the files by the amount I deleted because I kept running out of space on the D: drive.
I had a couple of options to free up space on the D: drive - move tempdb or move the other log/database files to our newly configured F: drive with 14TB of free space. I decided to move tempdb because it was as easy as executing the following command and restarting the SQL service.
|
|
By moving tempdb we had minimal downtime and I gained approximately 122GB in free space. While that gave me a little more room to shrink the old data files, it still wasn’t quite working as I wanted, so it was back to the drawing board.
Trying to shrink the files in huge chunks of 300GB or more was too much, it was slow and resulted in blocking of the inserts into the old database. I found a solution that seemed promising and would involve shrinking the files in much smaller bits in a loop, so I figured I’d try it. It took a little bit of poking to get the right number to shrink in every execution, but I eventually ended up using something similar to this:
|
|
I’d run the script against each file separately to fully recover the disk space from the month that was deleted. Again it was slow, but it worked.
I’m aware of all the issues with shrinking database files, and no, I wouldn’t normally do it. However, shrinking the files was necessary to move the project forward, as I had to get around the lack of disk space.
Just Use the New Drive
Now that I had a script to migrate the data relatively quickly (the PowerShell one), and had a script to shrink the old data files, you’d think I’d be all set to just run with this project, right?
Not so fast.
When I set up the new TrafficLogs database I put the data files for the archive (the old stuff being migrated) on the drive with the spinny disks. We didn’t think about using the new F: drive with 14TB of free SSD space to use, mainly because it wasn’t going to be enough for the entire migration. But after a few weeks, I decided to use that drive for a few reasons:
- They were NVMe SSDs. Which meant writing to them was much faster than writing to the the spinny drives
- It was about 14TB of free space, which let me move a huge amount of data without worrying about shrinking immediately. I could punt some of the whack-a-mole with the disk space.
Unfortunately, the only issue with doing this was once I filled the 14TB of disk space, I had to migrate the datafiles all back to the spinny drives. Which I did at the end of March 2019 after I ran out of drive space.
Was this ideal? No. Was it a pain? Yes. But again, it moved the entire project forward and I was still slowly getting all the data migrated over.
Drives, Please Don’t Die
In early May 2019, I was still plugging away at migrating data. At this point, I was back to where I started - copying data from the old database on the spinny drives, inserting it into the new database, deleting the old data, and then shrinking the files all on the same drives.

After months of doing this, I was seeing a noticeable slowdown in the process. The read/write delays on the drives had increased since January. The average delays of reads were over 100 milliseconds and about 80 milliseconds for writes.
The overall response time was terrible.
I was struggling with PAGEIOLATCH_SH waits as I was trying to insert data into the new tables.
We had been using the spinny drives for years, and I had been hitting them non-stop for about 4 months. I was very worried the drives were going to fail before I was done migrating all of the data.
Thankfully, they didn’t. I eventually was able to move all of the old data over to the new database. It only took 6 months to complete.
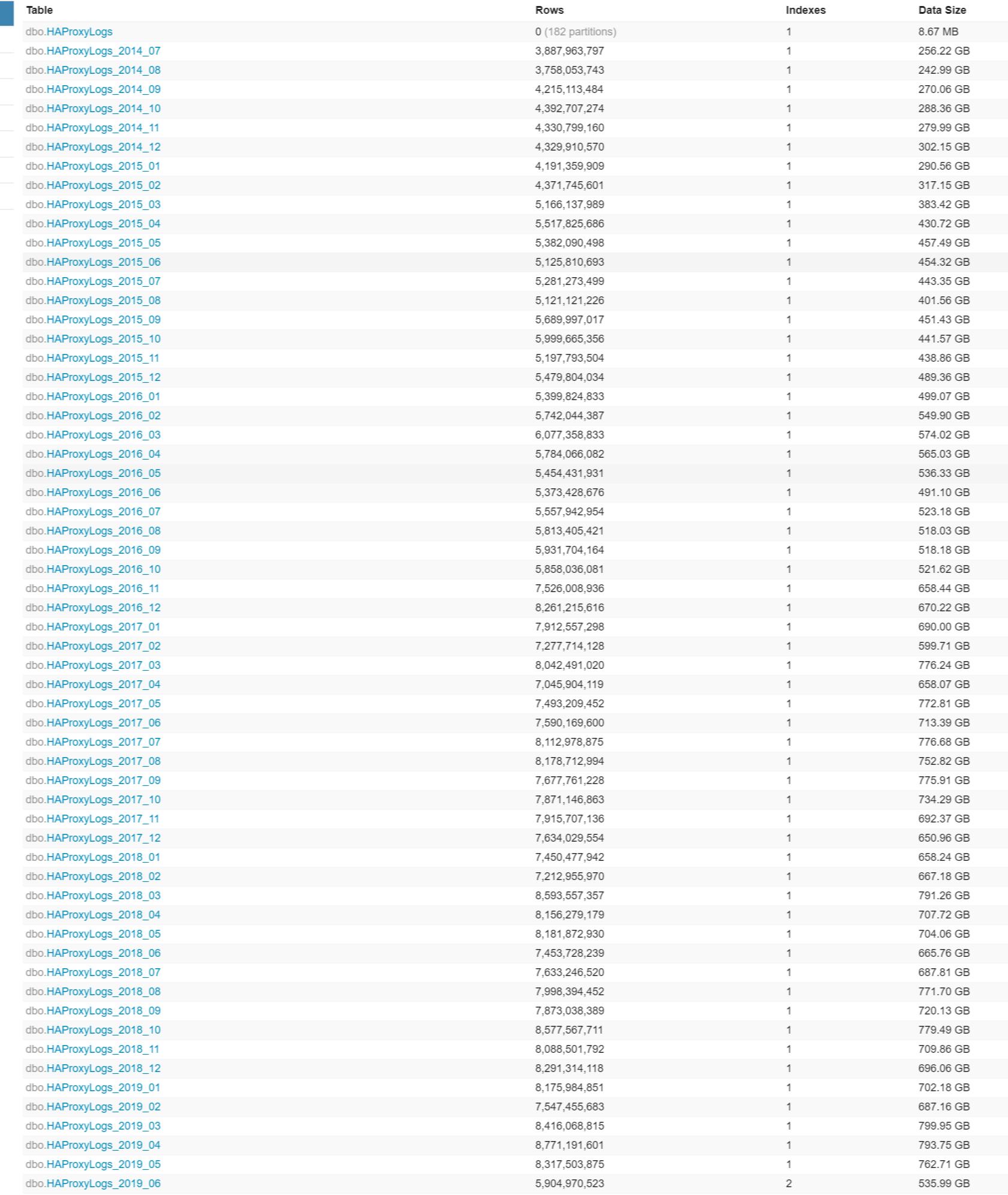
I was done, but not really. We still didn’t have the new servers which meant every table created would still need to be migrated until we had them, and had cutover to the new servers and database.
The moving target was still moving.
Finally, New Hardware
The plan was to get the new servers in June/July, but the purchase was delayed several months. After respeccing them to have all NVMe SSD storage, they finally arrived in late September. To make the final migration of the new hardware as easy as possible, from June through the end of September, I moved one table a day, keeping things up to date.
In early October, the new servers were ready for me to start installing SQL Server on them. The end was near.
After lots of fussing with the Windows Server install, I eventually got installed SQL Server 2017 on both of them. It was time for the next obstacle moving the gigantic databases over.
Backup and Restore Failure
The most obvious way to move a database from the old server to the new server is, of course, to take a backup and then restore it. So, that’s what I did, or I should say, tried to do. I say tried because when I took the backup, I set the script to write it out on the new server, but unfortunately, the backup took most of the space which meant I couldn’t restore it. It was a bit of a facepalm moment.
We’re a very lean shop when it comes to hardware, and this is by far our largest chunk of data we have to store, so there wasn’t a place anywhere on the network to store a 33-38TB full backup temporarily, while it was being restored to a server.
Time for more juggling.
Copying Tables…Again
Since I wasn’t able to take a backup and restore it, I was back to square one, trying to figure out how to quickly move this data. After spending almost the entire year moving tables one by one, the idea of having to do it all over again pretty much drove me to tears, but that’s what I tried next.
I would be moving from server to server within the same datacenter and rack, so I wanted to see how fast it would be to use various methods to bulk insert the data from the old database to the new one. I tried:

- PowerShell method - took 36 hours to move one table with 4 billion rows
- SSIS version - took 2.5 days to move the same table
OPENROWSET- took 16 hours to move 650 million rows
PowerShell was the winner when it came to speed, but Nick Craver wasn’t convinced. He decided to try it. He wrote a little LINQPad script and after running it he finally believed me that moving this much data sucked.
At this point, I was devastated because it looked like I was going to have to migrate everything for a second time.
Time to Try an Availability Group
I really, really, really did not want to move hundreds of tables again, so I threw out the idea of using an availability group to automatically seed the databases to the new servers. We already have AGs throughout our infrastructure, so I was familiar with using them, but I was unsure if it would successfully work for a database of this size.
Before starting, I pinged Sean Gallardy and asked if he thought it was possible to automatically seed a database of between 30-40TB - he guessed it’d be slow but possible, maybe taking 1-3 days. I was 100% ok with waiting 1-3 days, if it saved me months of moving tables again.
I decided to spin up the availability group on the Colorado server first, and if it was successful, I’d move to New York. In order to set this up, I would need to go through all these steps:
- Set up new Windows Failover Cluster with the two servers
- Take another backup, as I couldn’t use the first one because the database was in simple recovery instead of full. This meant waiting another 11.5 hours for the backup of the 33TB database in Colorado to finish
- Set up the AG and fingers crossed let it seed
- Initiate failover to the new server
- Destroy AG and shutdown old server
After backup in Colorado finished, I realized that we might have a small problem when trying to autoseed. The docs explain:
Automatic seeding requires that the data and log file paths are the same on every SQL Server instance participating in the availability group
The old servers had the data on E: and F:, and the new servers were using D:. To be certain there were no issues, I quickly renamed the drive on the new server to E: and moved the files over using:
|
|
By changing the assigned letter to the drive, I also had to move tempdb to the new drive, but once all that was done it was time to try setting up the availability group.
I spun up the temporary AG in Colorado, waited and watched SQL Server. I was constantly checking both DMVs sys.dm_hadr_automatic_seeding and sys.dm_hadr_physical_seeding_stats to see the status of the seeding process. I was concerned it would fail and we’d be back to the drawing board. After about 6 hours, it looked like we had seeded about 17TB of the database.
We also could see from our SignalFX monitoring of network traffic that something was happening. The SignalFX chart below shows we were averaging about 150 - 180 Mb/sec of traffic to a box that wasn’t being used by anything except for the database seeding.
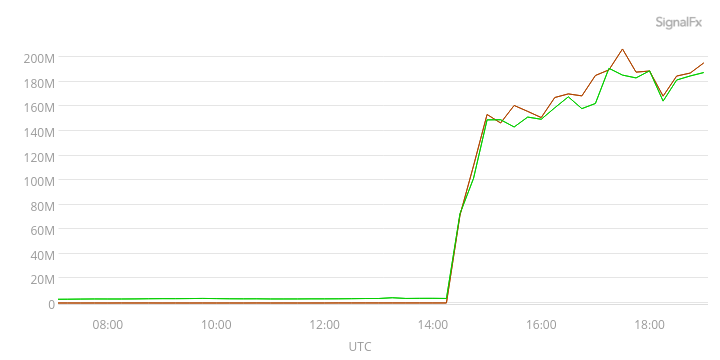
By the next morning, the seeding had finished and we had a database with all the tables on the new Colorado server. Progress!!
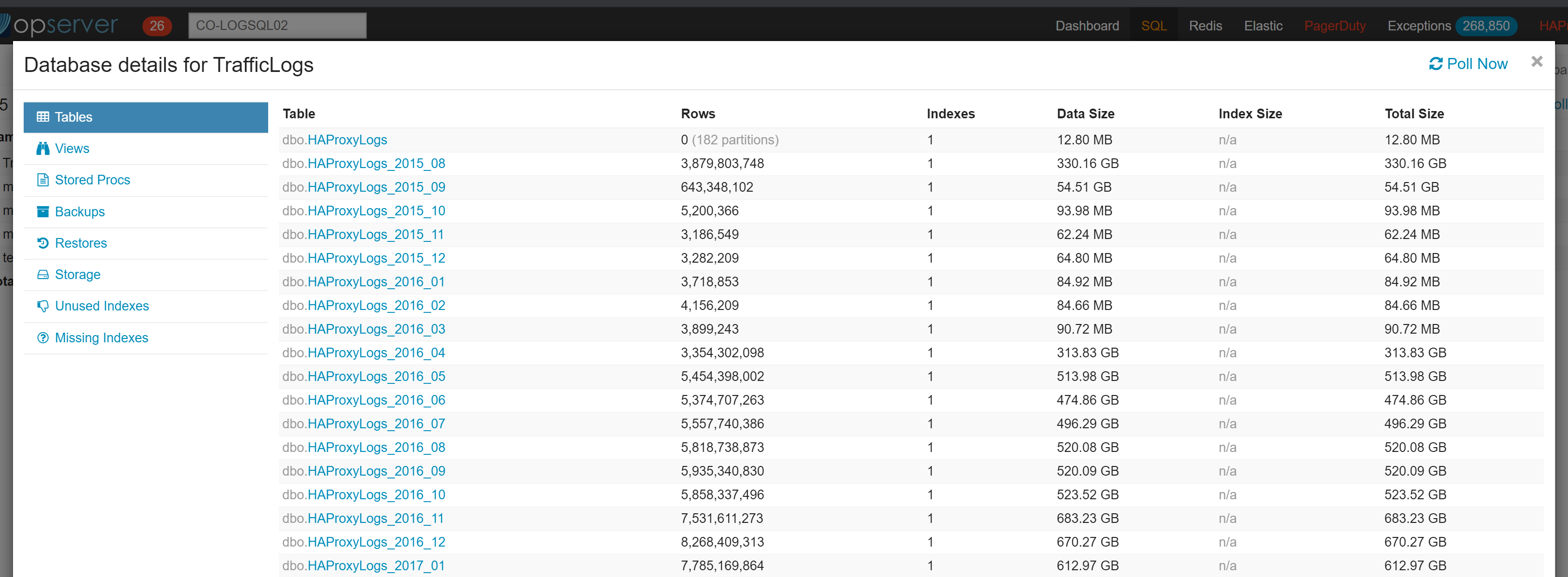
Before initiating the failover, I ran a DBCC CHECKDB on the new server aka the secondary in the availability group to be sure the database was in a good state, and after 22 hours it completed with no issues reported.
It was time for the failover. I was a little nervous about doing it, but we were ecstatic, shocked, and impressed (all-in-one) that it worked.
While all of this work was happening in Colorado, I kicked off the process on the New York server since the database was larger, and I knew it was going to take a long time. After taking 41 hours to backup the 40TB database, I was ready to follow all the same steps on the New York server. I set up the cluster, availability group, seeded the database, ran a very long DBCC CHECKDB, and finished with a successful failover.
The hardest parts were done, but it wasn’t quite time to celebrate. I still had some final work to do.
Final Cleanup

We finally had the new servers in place with the databases, but we didn’t have the new traffic log data flowing to the new servers quite yet. The service that sends the traffic logs (Traffic Processing Service aka TPS) was still pointing to the old database. This was done purposely, to not interrupt any of the teams using the data. The idea was, once the servers were in place, we could side-by-side release the new version to push data in both places for a period of time (by sending syslog traffic from HAProxy to both servers). This would allow teams to port their processes to the new database and table structures in a gradual way.
The week after the failover, we released the new traffic processing service and I did a few more days of data migration from the old server. I also destroyed the availability group and the windows failover clusters. Once all that was done, it was finally time to celebrate.
Final Thoughts
During my time as the DBA at Stack Overflow, I’ve had the opportunity to work on various large projects (some documented here and here), but none have taken as long as this one. This took about 11 months with all of the moving, validating, deleting, and juggling space.
I honestly love taking on these big projects. Planning the entire thing, and taking it from start to finish is extremely gratifying. Even though I automated the majority of the work, this project was incredibly frustrating and I definitely don’t want to do it again anytime soon (unless I have plenty of drive space and don’t have to juggle things for 11 months). This project was challenging in many ways, and considering I had to do the same work on two servers it was doubly challenging. In the end, I was very relieved to successfully use an availability group to seed the databases to the new servers, and finally be done with moving all the things.
Have you ever had to move multiple databases of this size? Were you lucky enough to have extra disk space to get it done? I’d be curious how others would have solved the problem of moving about 40TB of data (twice) with minimal free disk space? If you have thoughts, let me know.