This post has been rattling around in my head for months, and with SQL Server 2019 on the horizon, I figured I’d finally put my thoughts down, especially since I know we might hit some of the same issues when we upgrade.
A quick background, when I became the DBA at Stack Overflow, we had various versions of SQL Server in place — the majority were at some level of SQL Server 2016, each with a different CU or SP installed. We even had an instance of SQL Server 2012 still running. The bulk of our servers hadn’t been patched for 6-9 months, and we were just as behind in our Windows Updates…eeek. In a perfect world, all servers run the same version and CU. However, since we don’t have regular maintenance windows, tackling this would mean downtime - which meant it had to be a project not a one-off type of task.
When I kicked off this project, back in February 2018 (see I told you this has been rattling around in my head for months), we had ~30 servers, the breakdown of them was:
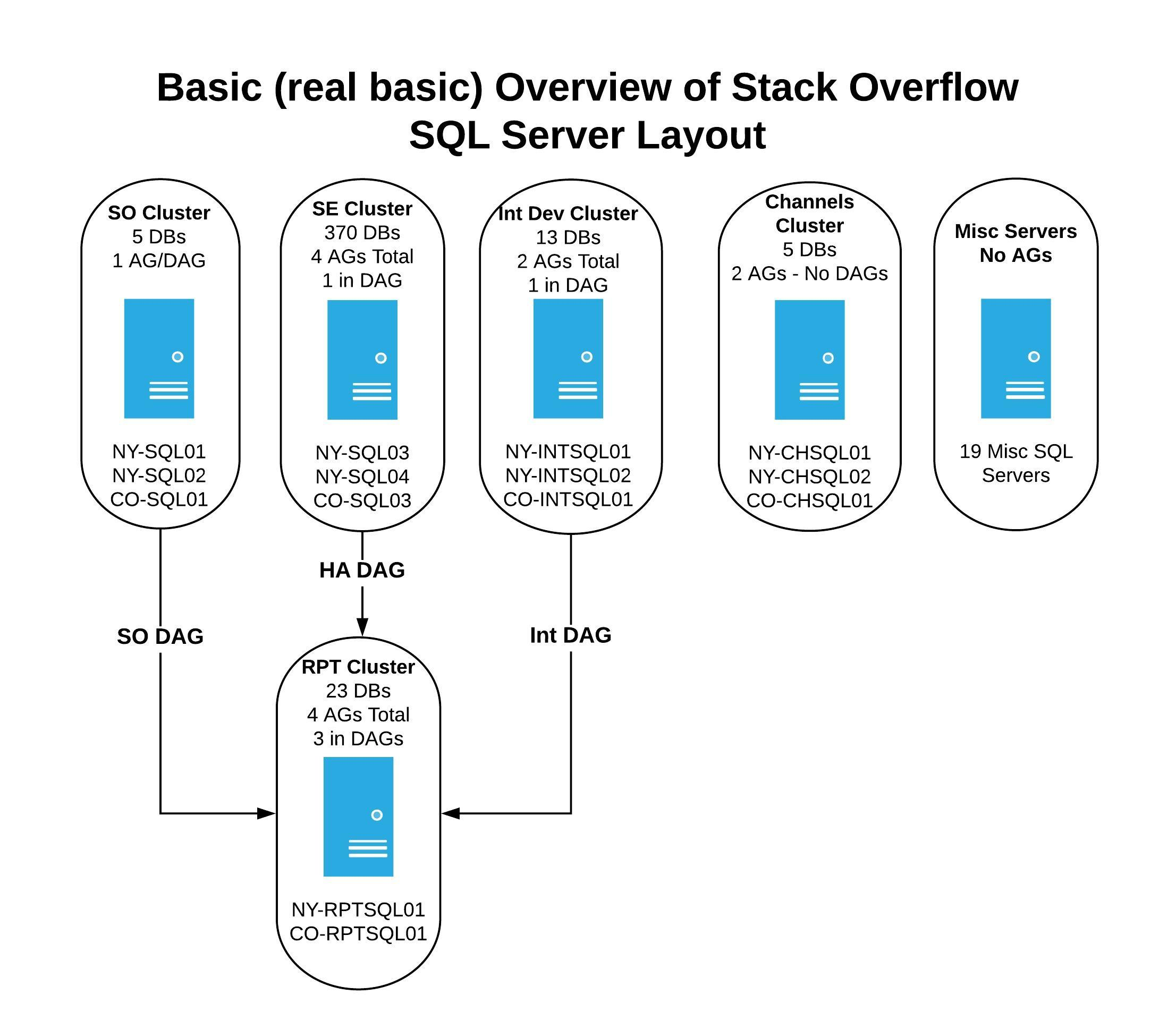
- 3 servers in the Stack Overflow cluster (2 in NY, 1 in CO)
- 3 servers in the Stack Exchange cluster (2 in NY, 1 in CO)
- 3 servers in a cluster for Internal Stuff - these power our internal applications (2 in NY, 1 in CO)
- 2 servers for Reporting Cluster - these power various reporting applications (1 in NY, 1 in CO)
- the remaining servers have miscellaneous functions like - lab/test environments, development servers, traffic logs, and many others used by various teams (located in both NY and CO)
We have various availability groups (AGs) running on the Stack Overflow, Stack Exchange, Internal Development, and Reporting servers. Adding another layer of complexity, we also have availability groups that are a part of Distributed Availability Groups (DAGs). The main clusters (SO, SE, and Internal) have data that flows from a handful of databases downstream to the reporting servers. It looks a bit like this:
The Initial Plan
With so many servers to upgrade, I needed to figure out the best path to get them done in the least amount of time, with the least amount of downtime. I started out by basically creating a spreadsheet of metadata. This spreadsheet included all the server names, the current software version (including CU/SP), the date of the last Windows Update, the team to notify before starting the maintenance, and the date the upgrade was completed. I also added a rudimentary risk level from low to high, and chose the levels based on whether the server was public, internal, dev, etc. Using this risk level, I prioritized the order in which to upgrade each server. Since all the servers hadn’t been patched in months, the patching plan for the day of the upgrade was:
- upgrade to SQL Server 2017
- run Windows Updates
- reboot as needed
- apply SQL Server CU update
- reboot and repeat as needed - mainly Windows Updates until everything was up to date
My goal was to complete all servers over the course of a month. That may sound like a long timeframe, but with only me touching them, it gave me wiggle room in the event there were issues. I started on the servers with the least amount of risk, this meant the Lab, Dev, and some of the miscellaneous servers. These aren’t customer facing, and are used internally, so if something went wrong we wouldn’t have public downtime. After patching ~15 servers I felt pretty confident that the upgrade of the rest would go fine…this was a mistake.
But I Followed The Plan
Moving to the servers in the AGs/DAGs, I knew I would follow this order for each cluster:
- Remote Secondary (CO)
- Local Secondary (NY)
- Local Primary (NY)
In between the NY Secondary and the NY Primary I’d perform a failover to let me hit the last server in the cluster. I also decided that I would do the remaining servers in this order:
- Reporting Cluster
- Internal Dev Cluster
- SO/SE - CO/NY secondaries
- SO/SE - NY primaries after a failover
This allowed me to get the majority of the upgrades done during the week, then we’d perform a quick failover on a weekend, during lower traffic, and I’d knock out upgrading the last two critical servers. Based on this, the CO reporting server was up first.
All boxes on the patching plan were ticked for this server, and when it came back up after the final reboot, I checked our instance of OpServer and everything was green and syncing; I thought ‘Woot, everything is great.’ Since we use readable secondaries, I wanted to perform a touch test on the databases in the AGs and DAGs to make sure everything was working. I logged into SSMS, but when I attempted to query any database in a DAG they weren’t accessible. I couldn’t read from them. This was a giant ‘oh crap’ moment.
I frantically started checking the server to see if there were errors. There was nothing. Nothing in the logs, and no errors from the installation. From what I could tell, everything went as expected. Then why couldn’t I read from the databases? After doing a bit of research, I found it was because the secondary was a higher version from the primary. Initially I thought, ‘OK, I’ll upgrade the NY reporting server and everything would be fine’, but then I remembered these servers are downstream in the DAGs. Uh oh.
If I upgraded both reporting servers, which receive data from 3 DAGs (SO/SE/Int Dev), and those are all a lower version of SQL Server, both reporting servers would be totally out of commission until the upstream servers were all upgraded. All this would result in major downtime for reporting and wasn’t going to work.
I did research, pinged people on Database Administrators Stack Exchange, and poked my co-worker Nick Craver about it. From everything I heard and read, the behavior was expected, but incredibly difficult to deal with if you’re not upgrading everything at the same time, or in a short amount of time. I wanted to spread the upgrades out over a month to make them manageable, but when they go out of commission because of a upgrade, that timeframe went out the window.
All this left me in a state of confusion. How the heck am I going to upgrade these with basically zero downtime, and ensure they don’t become unreadable for days?
My plan blew up — I couldn’t do the upgrade in the original order and timeframe that I wanted.
Back to the Drawing Board
Since we couldn’t be without both reporting servers for days, that meant I needed to come up with a new plan/timeframe to get this done. It would also need buy-in, because at some point we’d have more downtime than initially expected.
Microsoft recommends upgrading servers in this order:
- Upgrade remote secondaries
- Upgrade local secondaries
- Manual failover of the primary to the local secondary
- Upgrade previous primary
- Failback to previous primary
As you can see, that’s what I was following. The problem comes in when the server is in a Distributed Availability Group. I did the CO reporting server first, and ideally we’d do the NY version next, but since these are downstream in 3 DAGs, both NY and CO would be completely unreadable until the primaries upstream in the DAGs are upgraded. This means we automatically have reduced service with the servers, I can’t move to the CO secondary in the Internal servers because it’ll become unreadable like the reporting servers. As I move outward, the reduced service grows. So now what am I going to do?
Thankfully, I have a lab environment to test with. If you don’t have one, make one. I have 4 VMs that I set up to mimic our AG/DAG environment. This allowed me to test the upgrade order of the servers, perform failovers, verify the AGs/DAGs came back online, etc. After multiple failed attempts at getting the order right, I finally figured out that I would follow the same order and pattern that I was using, just not at the cluster level - it would be based on location instead.
The new plan would be:
- Upgrade all local NY secondaries in a DAG/AG - doing this makes them completely unreadable
- the NY secondaries in the Internal, SE, SO clusters
- Upgrade all remote CO secondaries in a DAG/AG - doing this makes them completely unreadable
- the CO reporting server was done, this left the CO servers in the Internal, SE, SE clusters
- Perform a failover in a specific order
- Reporting Server - failover to CO - this makes the entire cluster unreadable until all upgrades are finished - failover non-DAG availability groups, then failover the DAGs - hope that when it shows it’s syncing it really is, since we won’t be able to query anything
- Internal Server - failover to NY secondary - failover DAGs first, verify it’s syncing to reporting, then failover AGs
- SE Cluster - failover to NY secondary - failover DAGs first, verify it’s syncing to reporting, then failover AGs
- SO Cluster - failover to NY secondary - failover DAG
- Verify that everything is syncing or at least verify that everything appears to be syncing - I’m looking at you reporting servers
- Upgrade the former primaries in NY - reporting, internal SE, and SO
- Verify that all databases are syncing - most likely they aren’t, so running
ALTER DATABASE [<name>] SET HADR RESUME;should resolve any syncing issues - again looking at you reporting servers - Perform any failovers to reinstate a primary. For us, this only applies to the reporting cluster. When we failover within NY, we just let the new primary stay primary until we need to failover again - this minimizes downtime for us.
You can see that this deviates from the recommended order by Microsoft because we did the local NY secondaries first. This was done in the event something catastrophic happened in NY, and we had to fail to CO. We knew CO was still up and running since we could query it. If we had upgraded CO and made it unreadable, we wouldn’t be able to query it and confirm things were syncing properly for an extended period of time. The thought of this made us uncomfortable.
I tested and retested this plan in the lab environment to get it down before attempting this on any of the critical servers. The only real issue was the reporting servers would be out of commission until the rest upgraded. This meant everything would have to be upgraded fast, so we did not have reporting unavailable for too long. Based on this, it was decided we’d do the local NY secondaries on a Friday, then perform the rest of the upgrades and failover on a Saturday - this meant downtime, so we had to give plenty of notice to the community before tackling it.
In the few days before the upgrade, I wrote up the playbook for the weekend. To minimize downtime and to get the remaining 11 servers upgraded quickly, there were 3 of us who were going to be doing the last upgrades, so I wanted everything documented. The playbook had every step outlined, who was doing what to which server, SQL code for each step (if needed), what was to be installed on each server, the order of failover of AGs…everything. This was my first major upgrade and I was a nervous wreck, I didn’t want anything to be missed or to go wrong, so I probably overplanned, but why not, right?
The weekend came and went, and we had no issues with the upgrades. When we failover our main SO/SE clusters, we typically put the sites in read-only mode, just to be safe that nothing crazy happens when SQL is failing over - for this upgrade our downtime/read-only time was < 10 minutes which was far less than we expected. If you’re super curious, you can watch a recording of the livestream, though I’m not sure why you’d want to sit through ~3 hours of us talking about upgrades.
In the end, I learned a bunch from this. I figured out how best to upgrade to new versions of SQL Server when Distributed Availability Groups are in play without making servers unreadable for too long. I also learned just how darn handy having a lab environment is, and that I super over-prepared/planned for the days of the actual work. I’m not sure if this will help anyone else in the future, but now I know to avoid these landmines when upgrading.
I also know there are probably plenty of other landmines I can hit when we move to SQL Server 2019.